> qqachisq(10, 200, .5, 3, achisq1, "-2*LLR")
We studied five different approximate pivotal quantities for making inferences on the two-parameter gamma distribution:
Each has the same asymptotic chi-square distribution and each can be used for deriving parametric tests of hypotheses and joint confidence regions. In practice, with small samples, which will give the best results? In an application where you don't know the true value of the parameters, it is impossible to tell. The mathematical theory to derive the small-sample properties is formidable. The only simple way to see how the different alternatives will work in practice is to try them on computer-generated data similar to the data expected in practice, and see what they do.
I have written a suite of functions (which run equally well in Splus or R) to simulate data from the two-parameter gamma distribution, compute the pivotal quantity for each sample, and compare the observed distribution of the pivotal quantity with the asymptotic chi-square distribution on a QQ plot.
The gamma distribution is parameterized with shape parameter be (beta) and mean mu.
me.gamma() computes moment estimates and other statistics for the two-parameter gamma; it is used to give starting values for iterative calculation of the maximum likelihood estimates in mle.gamma().
> me.gamma
function(x)
{
xam <- mean(x)
xlgm <- mean(log(x))
xs2 <- var(x)
mu.me <- xam
be.me <- (xam^2)/xs2
data.frame(n = length(x), xam, xlgm, xs2, be.me, mu.me)
}
> mle.gamma
function(x)
{
stats <- me.gamma(x)
mu.ml <- stats$mu.me
b0 <- stats$be.me
repeat {
b1 <- b0 + (stats$xlgm + log(b0/stats$xam) - digamma(b0))/
(trigamma(b0) - (1/b0))
if(abs(b1 - b0)/b1 < 1e-10)
break
b0 <- b1
}
be.ml <- b1
be.se <- sqrt(1/(stats$n * (trigamma(be.ml) - (1/be.ml))))
mu.se <- sqrt((mu.ml^2)/(stats$n * be.ml))
data.frame(be.ml, mu.ml, be.se, mu.se, stats)
}logl.gamma() computes the log-likelihood function for the two-parameter gamma, given the sufficient statistics xam (arithmetic mean) and xlgm (log geometric mean).
> logl.gamma
function(be, mu, xam, xlgm, n)
{
n * ( - lgamma(be) + be * log(be/mu) + be * (xlgm - (xam/mu)))
}achisq1() uses logl.gamma() to compute -2 * LLR.
> achisq1
function(x, be, mu)
{
est <- mle.gamma(x)
logl.ml <- logl.gamma(est$be.ml, est$mu.ml, est$xam, est$xlgm, est$
n)
logl.tr <- logl.gamma(be, mu, est$xam, est$xlgm, est$n)
-2 * (logl.tr - logl.ml)
}boot.gamma() generates nboot independent samples of size n from the two-parameter gamma specified by be and mu, and arranges them as columns in a matrix. The user-supplied function myfun is then applied to the columns of the matrix to give nboot independent realizations of the statistic; I used achisq1 to get realizations of -2*LLR. Because Splus uses a rate parameter and R uses a scale parameter, I scaled the random gamma data by (mu/be) rather than use the rate or scale parameter of rgamma(), to ensure compatibility.
> boot.gamma
function(n, nboot, be, mu, myfun)
{
data <- matrix((mu/be) * rgamma(n * nboot, be), ncol = nboot)
apply(data, 2, myfun, be, mu)
}qqchisq() draws a generic chi-square QQ plot, plotting the quantiles of a chi-square distribution on df degrees of freedom on the abscissa against the quantiles of the data on the ordinate.
> qqchisq
function(x, df, xlab = NULL, ylab = NULL)
{
if(is.null(xlab))
xlab <- paste("Quantiles of Chi-Sq (", df, " df )", sep = "")
if(is.null(ylab))
ylab <- "Ordered Data"
xv <- as.vector(x)
plot(qchisq(ppoints(xv), df), sort(xv), xlab = xlab, ylab = ylab)
abline(0, 1)
}qqachisq() calls boot.gamma() with user-specified function myfun, removes any NA values (which result when maximum likelihood fails, more likely to happen when n and be are small), displays the result on a chi-square QQ plot, and displays the observed percent at the theoretical 95th percentile.
> qqachisq
function(n, nboot, be, mu, myfun, main = NULL)
{
qach <- boot.gamma(n, nboot, be, mu, myfun)
qach.good <- qach[!is.na(qach)]
qchi2 <- qchisq(0.95, 2)
cover95 <- mean(qach.good < qchi2)
qqchisq(qach.good, 2)
title(main = main, sub = paste("beta = ", be, ", mu = ", mu, ", n = ",
n, ", conf. = ", 100 * round(cover95, 3), "% (", sum(qach.good <
qchi2), "/", length(qach.good), " )", sep = ""))
abline(0, 1)
invisible()
}Here is an example of how I used these functions to study the small-sample distribution of -2*LLR. I used R; the function call and the resulting plot are shown below.
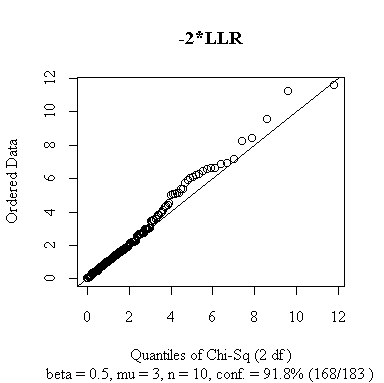
> qqachisq(10, 200, .5, 3, achisq1, "-2*LLR")
While the left tail of the distribution appears to follow a chi-square distribution very closely, the right tail of the observed distribution is longer than the chi-square right tail, the right-tail points lie above the diagonal, and the chi-square 95% point is lower than the actual 95% point. Note that 17 of the 200 samples could not be used because the maximum likelihood calculations failed. I don't know whether that means the maximum likelihood estimate didn't exist, or whether it did exist but my numerical methods weren't good enough to find it.